AlphaGo與過去的圍棋程式之差異
大橋:
想請王老師重新說明一下AlphaGo與過去的圍棋程式之差異。
王:
以前的圍棋程式,是記住一些局部的棋形,然後將這些棋形填入棋盤全局之中。一開始這種局部的棋形非常狹小,之後有稍微讓這些棋形變大了一些。程式會從這些學習到並且記住的棋形進行計算下一手棋的機率,或者根據對手下的前一手棋等等資訊來提示自己的下一著棋該怎麼下。所謂的蒙地卡羅法,就是將這些提示落點依序進行模擬,然後挑出勝率最高的一手棋。
大橋:
原來如此。
王:
然而這次出現的深度學習法,並不是記住局部的棋形,而是去學習全局性的棋形。根據他們在「自然(Nature)」雜誌上發表的論文來看,他們是從國際的網路對局服務KGS中擷取幾十萬局的棋譜讓程式學習,讓程式認識甚麼是圍棋,然後再讓AI自行對戰(左右互搏),讓程式更能理解圍棋的內容。
大橋:
所以是利用深度學習的方法讓程式學習全局性的棋形才會有那麼大的差異是吧。然後再用蒙地卡羅法輔助模擬來提高預測的精度。
王:
在和樊麾先生對局時,就是將這種方法所學習到的成果整理成一個程式版本來下的。這件事本身就很厲害了。
雷蒙:
就是所謂的策略網路(Policy Network)吧。
王:
此外,還導入了類似評價函數的價值網路(Value Network),讓程式的穩定性提高很多。
雷蒙:
AlphaGo的程式師說這個程式就是計算出人類下棋的著手機率然後選擇下一手棋。好比說,引起話題的第二局37手(圖A的黑1),這手棋人類會這樣下的機率據說是萬分之一。在那個局面下,AI似乎是在檢討30個左右的落點當作下一手棋的選項,但我覺得這些選項的每一手之後所假想的手順都不長。換句話說,都沒有細算的很深入,但也是因為如此,它才可以去考慮這種萬分之一機率的棋。
圖A
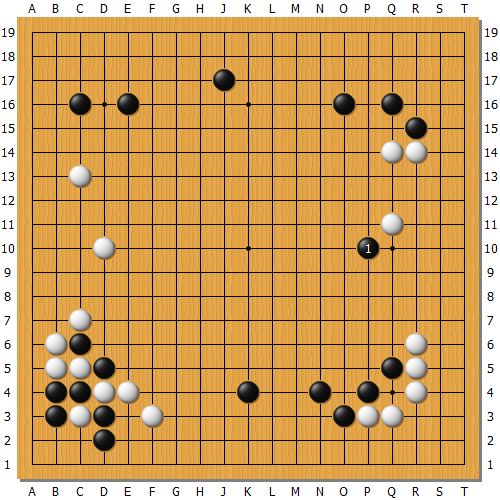
王:
那手棋恐怕已經不是參考人類下的棋了。感覺起來它是在選擇著手時進行自我學習,然後自己選出了這手棋。
雷蒙:
倒過來說,與第四局李世石勝利相關的第78手棋(圖B白1),似乎就不在AI假定的範圍之內。我的理解是很有可能是因為當時的盤面非常狹窄,使得AI必須細算的手順變長,讓它可以挑選的落點選項變少,使得系統資源變少的關係。(譯註:從這樣的說法來看,其實羅洗河九段賽前所說的「訣竅」是非常正確的)
圖B
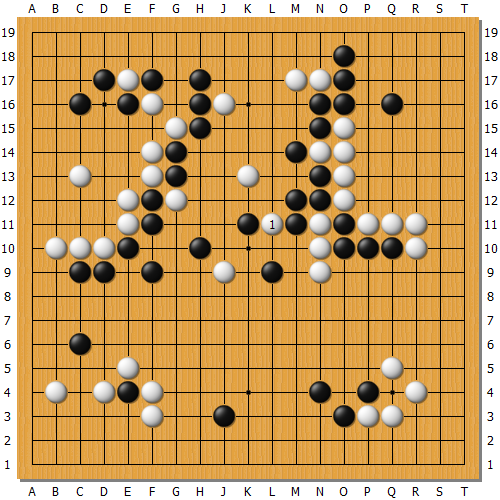
王:
從李世石先生下出那手挖之後,電腦的落子速度很快耶。
雷蒙:
就我聽到的說法是為了怕限時用完,所以有限制電腦每一手棋思考的時間。這個局面對人類來說,恐怕會希望能思考到一個小時以上吧。
===
相關系列文章:
沒有留言:
張貼留言