第二章 AlphaGo的思考方式
在前一章中,我們確認過了「I Love You」的翻譯思考方式,而AlphaGo使用的其實也是同樣的手法。接下來,我們就用簡明易懂的「碰長定石」為例來看看它怎麼思考吧。
1圖
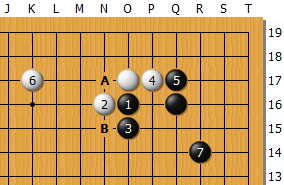
其實AlphaGo並不是把上圖這個型辨識成碰長定石,而是之前利用統計與機率導出了這個型,並且把一塊形狀當成一個群組。
換句話說,和碰長定石沒有關係,就算是出現在棋盤上其他地方,它也會判斷成只要黑1碰來,白棋就有60%的機率會下2扳。
或者它也會從資料庫中尋找有沒有像白A長等等其他的招數,然後根據搜尋出來出現機率最高的結果選擇下出白2這一著。
但其實AlphaGO並不知道白2這手棋到底是好棋還是壞棋。即便是如此,為何AlphaGo還是可以靠著統計與機率的搜尋方式來贏棋呢?這個我們後續再談。
回到圖1,當白2扳時,黑棋也有70%的機率會3長,或者黑棋也可能會走B扳,但程式還是會根據機率搜尋挑出出現機率最高的一手棋,並且持續搜尋接下來的各手棋、並做出選擇,然後假定會變成到黑7為止的結果,先做出一個型。至於途中發現的其他變化形態也會一塊塊的做成群組,然後放入選擇名單之中。
這就和「I Love You」的翻譯思考方式是一模一樣。
到這裡為止的解釋,可能有人會誤解為AlphaGo是光靠定石(型的群組)來下棋的,所以我想用2圖的棋型來幫助大家更進一步地理解它的思考方式。
2圖
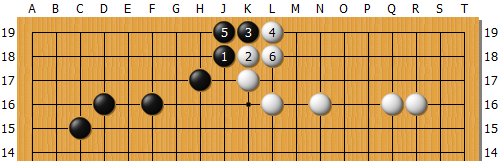
像2圖這樣黑地與白地都已經有相當程度完成的局面中,有50%的機率黑棋會走黑1尖。接著白棋會有80%的機率下2擋,然後一直到白6為止也都是靠統計與機率推斷出會變成這個型態。
更進一步,它會搜尋出只要黑1尖,就有70%的機率會走成白6為止的型態,然後就把白6為止的一塊型態當作一個群組學習起來。
然後我們再把說明拉回到碰長定石上。
3圖
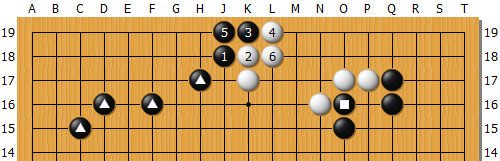
像3圖那樣,假定先在棋盤上填入碰長定石的群組,後續也根據統計與機率的搜尋方式導出到黑△之後的發展,最後的黑1到白6也用搜尋的方式填入這個群組來思考。
至今為止採用了蒙地卡羅演算法的圍棋程式,都是在黑1下出後,使用亂數搜尋的方式去計算白2、甚至是黑3以下的各手棋,這樣要導出圖3中白6為止的結果是非常困難之事。
不過利用深度學習,就可以參照儲存起來的棋譜資料庫,辨識出黑1到白6的棋型會頻繁出現,因此把這個棋型暫時先做成一個群組。然後在棋局的進行中,搜尋各式各樣的棋型,做出暫定的終局圖,並且假定黑棋只要下□,就可以10目勝。
它就是經過這樣的思考方式,從出現率最高的變化中,搜尋出最單純的一手棋當作它的次一手棋。
以上的這些過程,用我們人類的角度來看,就是一般所說的「一廂情願計算(勝手細算)」,但是對於電腦來說,這可是一種精確度高到嚇人的一廂情願計算。
這裡還有一個理解AlphaGo實力的重要關鍵,就是它不一定下的是「最佳」著手。
在下一章中,我想來解說一下我所看到的AlphaGo實力。
===
相關系列文章:
沒有留言:
張貼留言